现在说到爬虫,大家都会或多或少地将python和爬虫联系在一起,归根到底,是因为python丰富的生态和灵活简单的语法。同时基于python存在有几个强大的爬虫框架,极大地降低了爬虫的难度,提高了编写程序的效率。最近我也体验了一下scrapy,算是做一个入门的记录吧
简介
Scrapy是一个用于爬网网站和提取结构化数据的应用程序框架,可用于各种有用的应用程序,例如数据挖掘,信息处理或历史档案。
——翻译自官网
推荐直接查看官网,里面甚至有完整的scraoy教程,简直是深入学习框架的必备选择!
安装
在安装scrapy框架的时候,网上有许多方法,针对python的环境不同,可能存在奇奇怪怪的错误,这里我基于python3环境,预装了pip,亲测一遍过
预装环境
Windows 10 + python 3.7.0 + pip20.1 +virtualenv
同时请开启一个新的virtual环境来保证不会出现其他包的依赖冲突
前期安装组件
lxmlpyOpenSSLTwistedPyWin32
安装lxml
直接pip安装即可。这是python一个HTML、XML解析库,即使不用框架也是经常使用的
pip3 install lxml
安装PyWin32
官网下载对应版本的安装包双击安装即可 [pywin32]([https://sourceforge.net/projects/pywin32/files/pywin32/Build%20221/](https://sourceforge.net/projects/pywin32/files/pywin32/Build 221/))
安装剩余组件
这里首先要介绍wheel
wheel是python的一个打包格式,以前python主流的打包格式是.egg文件,但现在*.whl文件也变得流行起来。
wheel其实上是python上一种压缩打包的组件,有点类似于zip之类的,但在本文中你只要知道通过wheel文件格式文件你可以快速将一个库安装到你的python环境中
安装其实也很简单
pip3 install wheel
这样你的python环境就支持.whl文件格式的安装啦
接下来的步骤就是到各个官网上下载各组件的whl格式,注意要和你的python环境匹配
安装
pip3 install pyOpenSSL-19.1.0-py2.py3-none-any.whl
Twisted注意要和你的python版本对应
像我的环境就是
pip3 install Twisted-20.3.0-cp37-cp37m-win_amd64.whl
安装scrapy
所有依赖包安装成功后直接pip安装scrapy就不会有问题啦
pip3 install Scrapy
组件介绍
首先创建项目
在你想要放置爬虫项目的文件夹运行,xxx就是你的项目名
scrapy startproject xxx
顺便记录一下一些基本的操作
- 创建项目:
scrapy startproject xxx - 进入项目:
cd xxx #进入某个文件夹下 - 创建爬虫:
scrapy genspider xxx(爬虫名) xxx.com (爬取域) - 生成文件:
scrapy crawl xxx -o xxx.json (生成某种类型的文件) - 运行爬虫:
scrapy crawl XXX - 列出所有爬虫:
scrapy list - 获得配置信息:
scrapy settings [options]
创建完成后你可以看到文件夹下多了这些内容
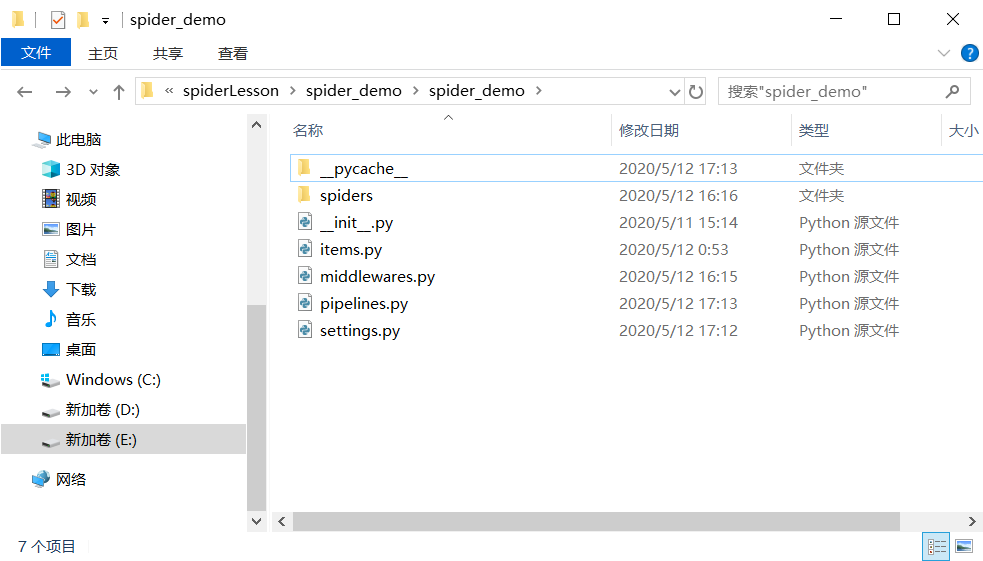
让我们一个个介绍这些组件(spider_demo是你的爬虫项目名)
scrapy.cfg: 项目的配置文件(在项目文件夹的平行目录下)spider_demo/spiders/: 放置spider代码的目录. (放爬虫的地方)也是你放爬虫具体逻辑的地方spider_demo/items.py: 项目中的item文件.(创建容器的地方,也是定义最终爬虫得到的结果格式的地方)spider_demo/pipelines.py: 项目中的pipelines文件.(实现数据的清洗、存储和验证)spider_demo/settings.py: 项目的设置文件.(爬虫的具体配置,包括启动某个中间件,启动关闭某个功能等)spider_demo/middlewares.py:定义项目的下载器中间件和爬虫中间件
感觉是不是还有点蒙圈?接下来简单介绍一下scrapy运行的原理,这样相信就能更理解这些组件的作用了
官网的流程图

Scrapy是由执行引擎控制执行的
Spider发起请求给EngineEngine安排请求Scheduler和接受下一个爬取请求Scheduler返回下一个请求Engine将请求通过Downloader Middlewares发送给DownloaderDownloader爬取网页并将返回结果通过Downloader Middlewares发送回Engine- 引擎接受响应并通过
Spider Middleware转发给Spider处理 Spider的parse()方法对获取到的response进行处理,解析出items或者请求,将解析出来的items或请求,返回给EngineEngine将items发送到Item Pipline,将请求发送到Scheduler- 重复步骤1直到没有新的请求
总结一下上面步骤出现的组件
| 组件名 | 组件功能 | |
|---|---|---|
| Engine | 框架核心,负责整体的数据和信号的调度 | 框架实现 |
| Scheduler | 一个存放请求的队列 | 框架实现 |
| Downloader | 执行具体下载任务的单元 | 框架实现 |
| Spider | 处理下载得到的响应结果,提取需要的是数据(具体的业务逻辑) | 自己实现 |
| Item Pipline | 处理最终得到的数据,如进行持久化操作 | 自己实现 |
| Downloader MIddlewares | 在正式进行下载任务之前,可以进行一些自定义处理。比如设置请求头,设置代理 | 自己实现 |
| Spider Midderwares | 自定义请求和过滤响应 | 自己实现 |
相信这一套组合拳下来应该能对这个框架有了基本的认识,接下来就通过实战来强化一下记忆吧
简单应用
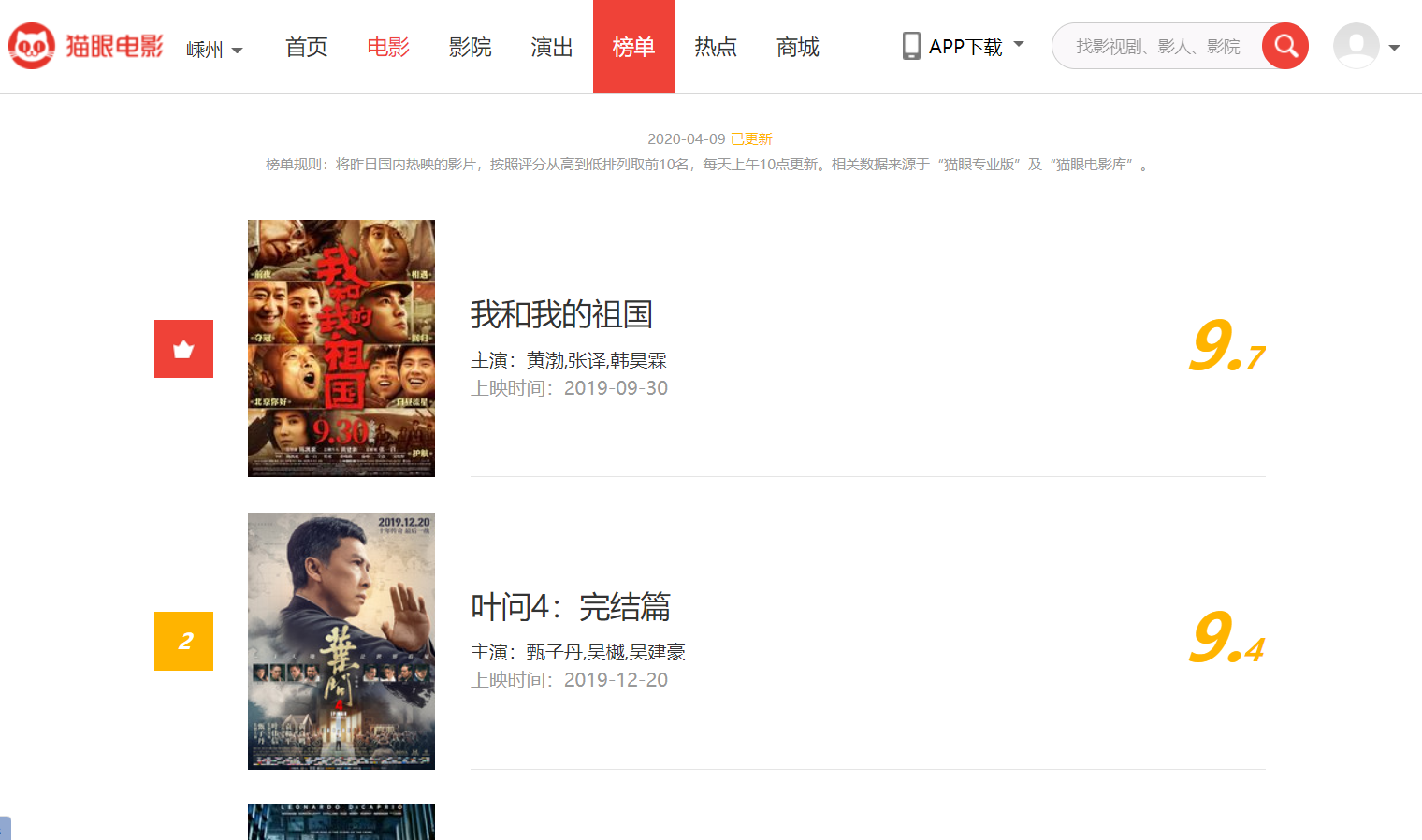
这次是根据网上通过爬取猫眼电影的排行榜做的一个demo,以后有时间再换一个更加复杂的demo
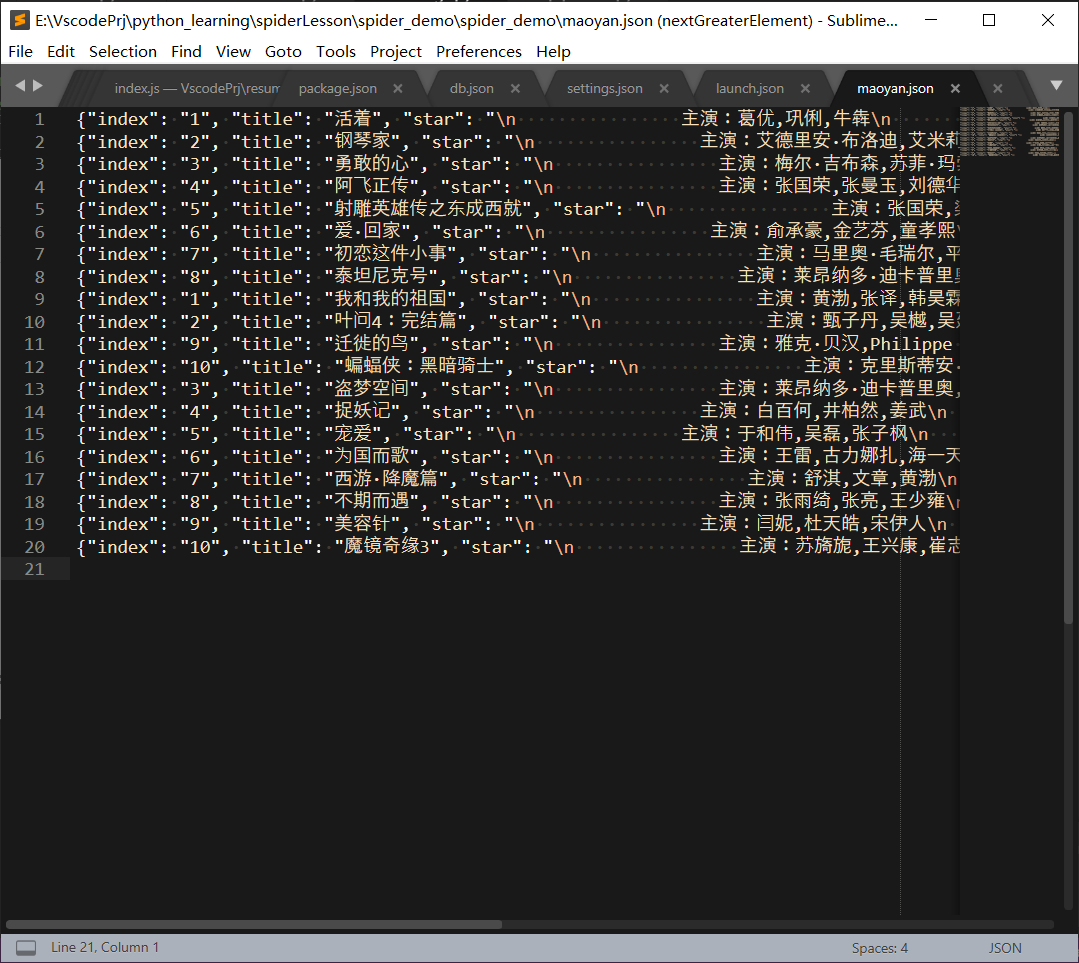
实现目标是爬取电影排行榜上的片名、分数和排名,同时将结果以json的格式保存在一个.json文件中
首先你要确定你需要爬取哪些数据,将你需要的数据记录到容器中,在item.py中进行编写:
import scrapy
#这里我们需要排名、标题、收藏人数、上映时间和分数
class SpiderDemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
index = scrapy.Field()
title = scrapy.Field()
star = scrapy.Field()
releasetime = scrapy.Field()
score = scrapy.Field()
接下来在Spiders文件夹下新建一个爬虫文件,例如我新建了一个MoyanSpider.py文件
import scrapy
from spider_demo.items import SpiderDemoItem
class MaoyanSpider(scrapy.Spider):
#这是爬虫启动的名称,之后启动爬虫就需要用到这个名称
name = "maoyan"
#可以爬取的域名可选列表
allowed_domains = ["maoyan.com"]
#目标爬取的网址
start_urls = [
"http://maoyan.com/board/7/",
"http://maoyan.com/board/4/",
]
#处理已经下载的页面
def parse(self, response):
dl = response.css(".board-wrapper dd")
#通过解析得到具体的数据存到容器中
for dd in dl:
item = SpiderDemoItem()
item["index"] = dd.css(".board-index::text").extract_first()
item["title"] = dd.css(".name a::text").extract_first()
item["star"] = dd.css(".star::text").extract_first()
item["releasetime"] = dd.css(".releasetime::text").extract_first()
score = dd.css('.integer::text').extract_first()
if score is not None:
item["score"] = score + dd.css('.fraction::text').extract_first()
else:
item["score"] = 0
#通过yield将结果返回
yield item
这里提一下,scrapy支持各种类型的解析,你可以使用python常见的三大解析库进行解析,但框架也提供了一种自己的解析方式(Selector)
- 选择器
Xpath
这里不详细叙述,以后有时间再细聊
同时我们需要在setting,py中对配置稍微进行修改(setting.py中有许多默认配置,这里只展示修改的部分)
#如果没有自动生成UA,就需要手动定义,但是每次爬取都是同样的UA容易出现验证操作,因此后面还会介绍一种随机生成UA的方法
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
#允许机器人协议,关于机器人协议的具体内容可以自行上网查找
ROBOTSTXT_OBEY = False
这样,基本就完成了一个简单的爬虫,只需要执行scrapy crawl maoyan(最后一个是你的爬虫名)
之后还有两个要点,一个是项目的持久化,一个是随机化User-Agent。
先看持久化,这里简单起见就示范将爬虫数据以json格式导出
这里需要修改pipline.py,至于为什么,相信看了之前的组件介绍应该能明白
import json
import codecs
class SpiderDemoPipeline:
def process_item(self, item, spider):
return item
class JsonPipline(object):
def __init__(self):
print("打开文件,准备写入....")
self.file = codecs.open("maoyan.json", "wb", encoding='utf-8')
def process_item(self, item, spider):
print("准备写入...")
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def close_spider(self, spider):
print("写入完毕,关闭文件")
self.file.close
然后在setting.py中开启自定义的pipline
ITEM_PIPELINES = {
# 'spider_demo.pipelines.SpiderDemoPipeline': 300,
'spider_demo.pipelines.JsonPipline': 200
}
至于随机化UA,先说明添加UA的原理
scrapy首先会读取setting.py里面关于UA的设置,然后经过middleware,如果没有进行自定义操作,就会将配置中的UA添加到请求头中。因此,想要实现随机化UA,实际上就可以在发起网页请求之前,在Download Middleware上做文章。
这里在middleware.py上做了修改,引入了第三方包fake_useragent
from scrapy import signals
import random
from fake_useragent import UserAgent
class RandomUserAgentMiddleware(object):
# 随机更换user-agent
def __init__(self, crawler):
super(RandomUserAgentMiddleware, self).__init__()
self.ua = UserAgent()
self.ua_type = crawler.settings.get("RANDOM_UA_TYPE", "random")
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
def get_ua():
return getattr(self.ua, self.ua_type)
request.headers.setdefault('User-Agent', get_ua())
同时在setting.py上做修改
DOWNLOADER_MIDDLEWARES = {
'spider_demo.middlewares.SpiderDemoDownloaderMiddleware': 543,
'spider_demo.middlewares.RandomUserAgentMiddleware': 400,
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,
}
# 随机选择UA
#这个是自己设置的,依赖于fake-useragent
RANDOM_UA_TYPE = 'random'
至此,一个简单的爬虫应用就实现了!
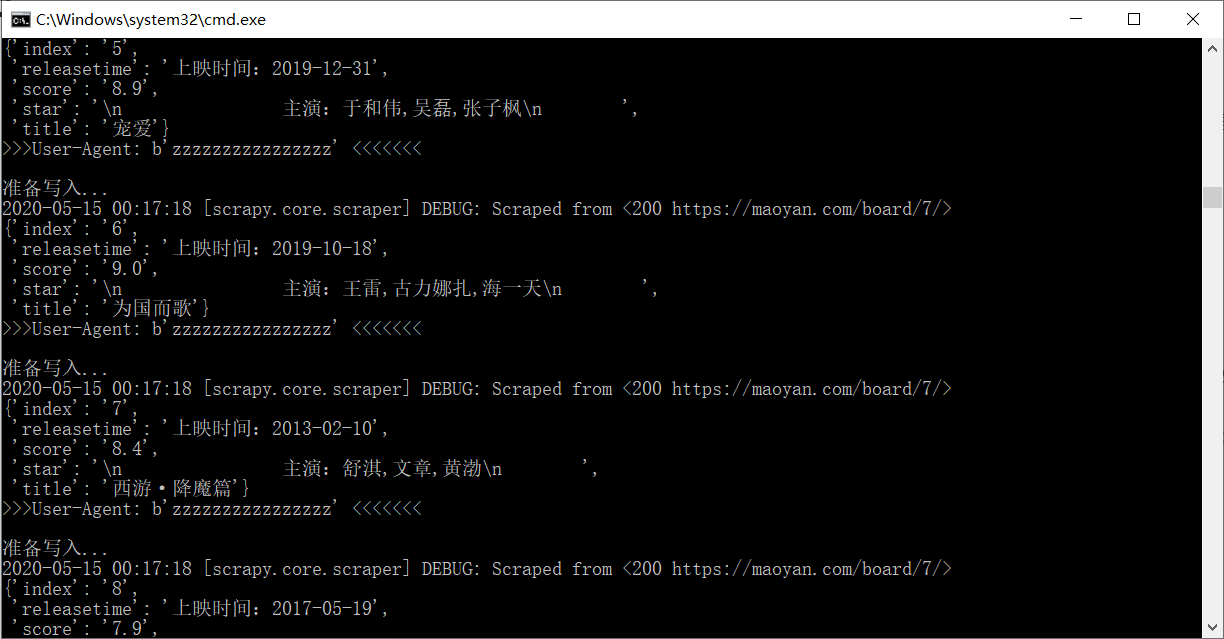
可以看见UA发生了变化
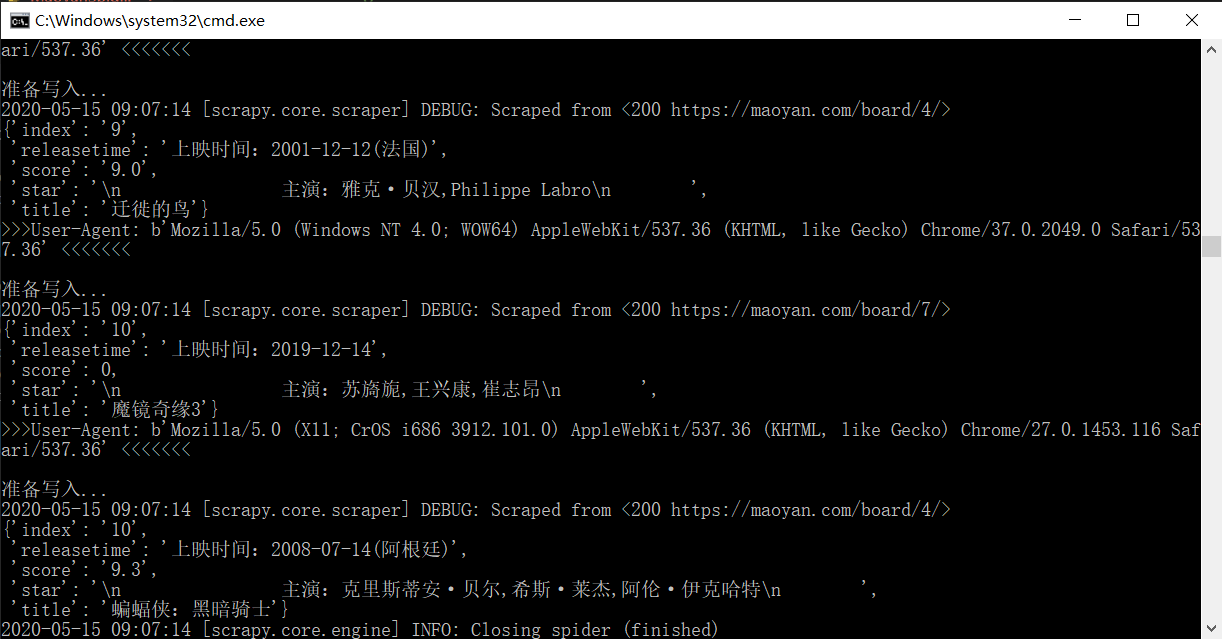
同时生成了一个maoyan.json文件