
1. 概述
金融行业、零售行业、电信行业等经常要对用户进行划分,以标记不同的标签,从而进行个性化的精准化营销行为。RFM模型,是以用户的实际交易或消费或购买或充值等(以下统称“交易”)一系列行为数据作为基础,从而进行用户群体的划分的,简单而又具有实际价值。RFM模型由三个指标组成,分别为:
- Recency:用户最近一次交易时间的间隔。R值越大,表示客户交易发生的日期越久,反之则表示客户交易发生的日期越近。
- Frequency:用户在最近一段时间内交易的次数。F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。
- Monetary:用户在最近一段时间内交易的金额。M值越大,表示客户价值越高,反之则表示客户价值越低。
可以看到这三个指标都是通过用户的交易行为计算得出的,这些指标基本上代表了用户是否活跃,购买能力,忠诚度等信息。而运营人员的目标是通过对每个用户的RFM指标进行计算,将用户群体划分为不同的种类进行区分,以便运营人员进行分析和精准化营销。参考图1所示:
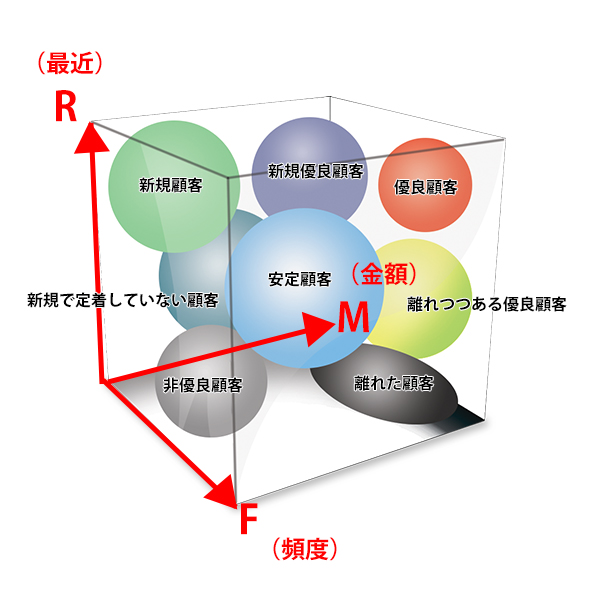
图1 用户分类( 看到一张日文的描述得比较好的图,就採用了,应该能够看懂)
可以把R、F、M每个方向定义为:高、低,两个方向,我们找出R、F、M的中值,R=最近一次消费,高于中值就是高,低于中值就是低,这样就是2_2_2=8种用户分类,从而分析出高价值用户,重点发展用户,流失用户等群体进行针对性营销动作。制定运营策略既要结合各类用户在产品中的占比,也要结合产品的实际业务逻辑。参考表1所示:
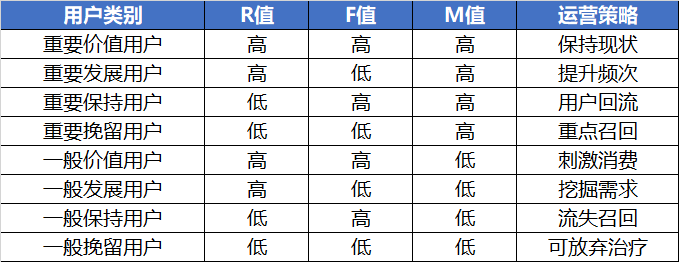
表1 不同用户分类的运营策略例
2.实证分析
2.1 数据预处理
从csv文件(某电商某段期间的真实运营数据)获取数据,包括用户ID,交易日期,交易金额等字段。数据概况如下:
- 特征变量数:4(USERID、ORDERDATE、ORDERID、AMOUNTINFO)
- 数据记录数:4442
- 是否有NA值:无
- (AMOUNTINFO)最大值:9188
- (AMOUNTINFO)最小值:0.01
对原始数据做缺失值处理和异常值处理。由于本次数据没有缺失值,则不需要处理。(如有,可根据需要进行删除或补充处理。)对于交易金额为0.01的交易金额数据,经确认为运营测试数据,做删除处理。对交易日期(ORDERDATE)进行日期转换,以便后续进行时间间隔的计算。
2.2 RFM得分计算
1、指定最近时间截点
由于数据中,最近的交易日期为2018年12月5日,则指定该日期为最近时间截点,所有时间间隔的计算都以该日期为参考点。
2、R、F、M数值计算
以用户ID(USERID)为主键,分别对交易日期(ORDERDATE)求最大值、对交易日期(ORDERDATE)做计数统计、对交易金额(AMOUNTINFO)求和,结合上述1中得到的最近时间截点,得到R、F、M的数值。
对得到的R、F、M的数值使用分位法做区间划分,一般分为5份。同时通过labels标签指定区间标志。对R而言,数值越大,离最近时间截点越远,其区间标志越小。F、M则和R刚好相反。
经过计算后的RFM数据分布可参考图2、图3所示:
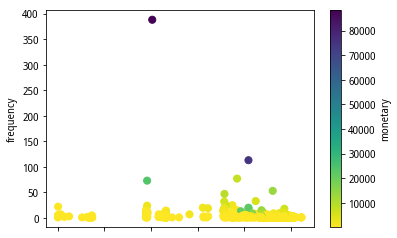
图2 RFM-散点图分布
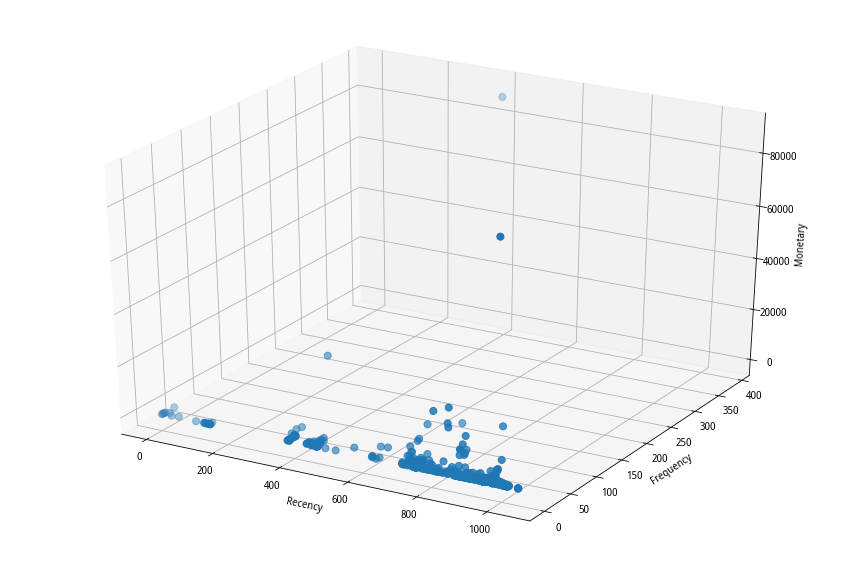
图3 RFM-3D图分布
从图2、图3可知,该用户群的早期客户数较多,交易频度集中在50以内,交易金额普遍不是很高。
2.3 权重计算
一般来说,权重计算多采用层次分析法(AHP)。金融公司中常用于个人信用风险评级模型的开发,而零售行业中的借贷评级,也可以借鉴该方法。利用AHP方法,先通过两两比较确定各个因素的相对重要性,再通过求解相对重要性计算指标权重。指标权重需经过一致性检验,即随机一次性比率指标CR越小越好(一般要求CR<0.1)。专家评分矩阵可参考表2所示:
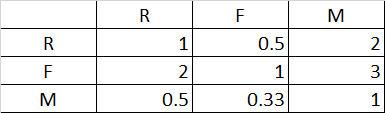
表2 专家评分矩阵
最终确定权重为:[W_R 、W_F 、W_M] = [ 0.30、0.54、0.16 ](详细的计算过程省略)由于本案例的指标只有3个,数量较少,不易混淆,所以也可以简单地直接设定。
2.4 基于RFM区间标志+分类规则的用户分类
第一种的分类方法是利用RFM区间标志+分类规则的方法(宋天龙,2017),可参考表1所示。以R为例,其中“RS分布”指RS的平均值,“高”指高于平均值。F、M雷同。其分类结果可参考图4所示:
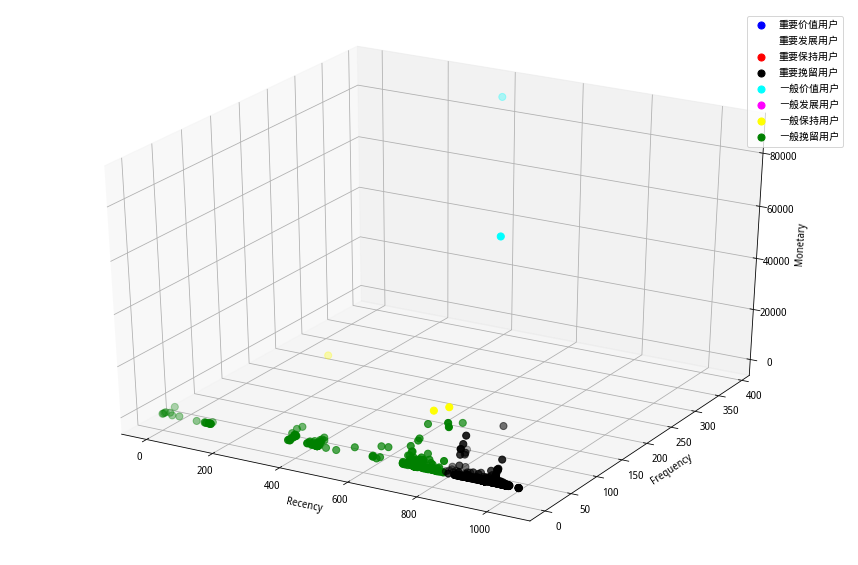
(图4 基于方法一的分类结果)
从图4可知,该用户群主要由重要挽留用户+一般挽留客户组成,另外有少部分一般价值客户和一般保持用户,严重缺乏重要价值用户和重要发展客户。
2.5 基于RFM实际数值 + K-means的用户分类
第二种方法是直接使用RFM的实际数值,结合K-means聚类方法进行分类,不使用RFM区间标签。在使用该方法的时候,要注意:
- RFM是否存在离散值,是否均匀分布
- RFM为不同量纲,需要进行标准化处理
- K-means聚类方法按照几类进行分类
离散值和标准化处理可按照常规的处理办法。离散值处理可使用MAD法,也可简单地按照取对数的处理。标准化处理可用z-score方法。本案例中,只进行了标准化处理。至于按照几类进行分类,可通过elbow method(详细可参考https://en.wikipedia.org/wi/Determining_the_number_of_clusters_in_a_data_set)方法,来推断使用分类数,如图5所示,取图中曲线下降趋势缓和的节点即可,即k=4。
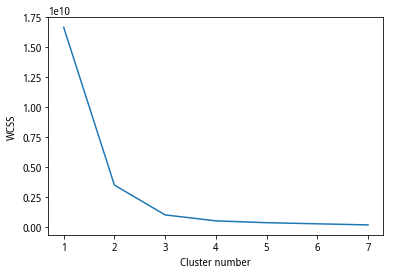
图5 elbow method
根据分类数=4进行K-means聚类分析。由于此时的分类类别不再是固定的8类,所以我们可将客户简单的分为k类星级客户。分类结果参考图6所示:
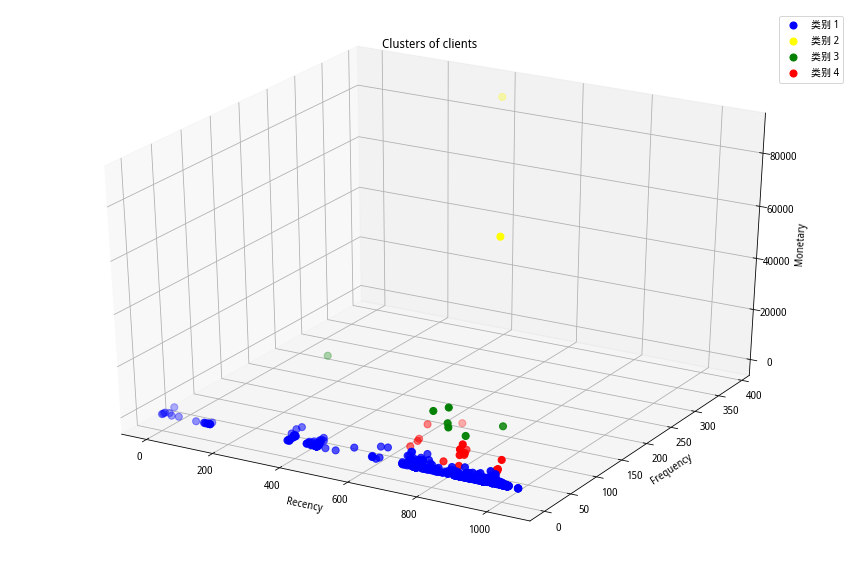
图6 基于方法二的分类结果
此时的用户分类只是简单地将用户进行分类,尚没有体现不同分类用户之间的区别。此时可取各分类的质心,并将其排名显示,结合了排名的分类结果可参考图7所示:
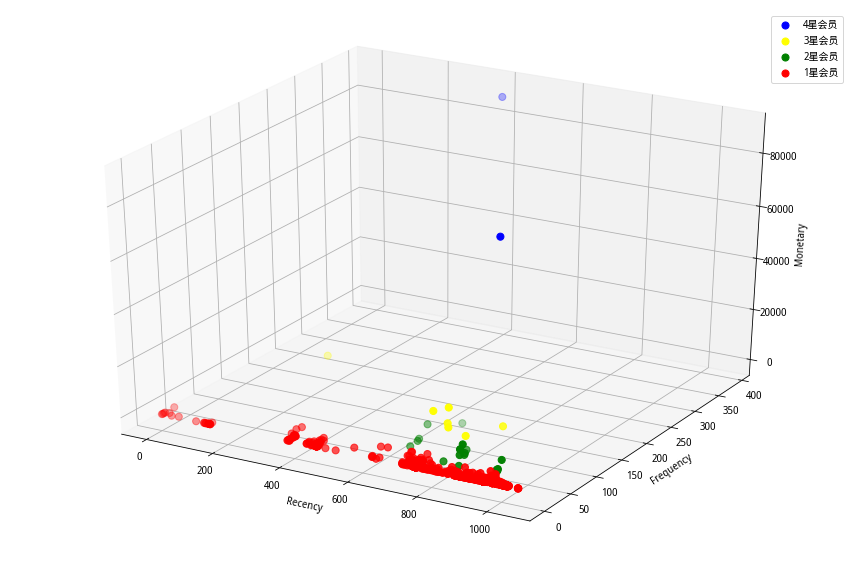
图7 基于方法二的分类+排名结果
可通过概率密度图来查看各排名用户类别的RFM分布情况(watermelon12138,2019),以3星会员为例,参考图8所示:
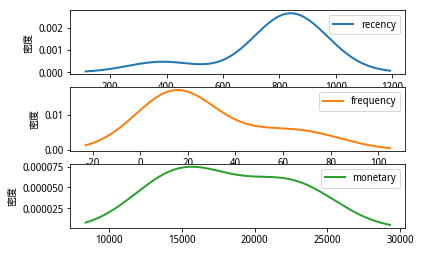
图8 3星会员的概率密度图
由图8可知,该类用户访问天数在800天前后,其交易频率集中20附近,而其交易金额则分布较广,从15000到25000不等。
2.6 两种分类方法的比较
从两种不同的分类结果来看,虽然基本都是分为4类,但4类的分法各自不同。前者在分类规则上更容易按照运营人员的期望进行分类,后者更加注重利用机器学习的自动学习能力,把更多的任务交给K-mean聚类来完成。前者虽然也计算用户的价值分数,但前者的分类并不依赖用户价值分数,用户价值分数仅仅只是参考;而后者通过K-means进行聚类,但无法进行用户类别排名,用户类别排名主要依赖于用户价值分数及RFM权重。
本文的源代码可参考笔者在JoinQuant的代码分享:
https://www.joinquant.com/view/community/detail/dee9aa758086d5a37923300e6b288456
参考文献:
- 宋天龙. 《Python数据分析与数据化运营》
- HarveyLau.《RFM-Clustering》 https://github.com/HarveyLau/RFM-Clustering
- watermelon12138.《K-means聚类算法、Pandas绘制概率密度图和TSNE展示聚类结果》https://blog.csdn.net/watermelon12138/article/details/86549474
- Wilame Lima Vallantin.《Apply RFM principles to cluster customers with K-Means》