
Redis概览
基础数据结构
string字符串list列表set集合hash哈希字典zset有序集合
string字符串
- Redis 中的字符串是可以修改的字符串, 在内存中是以字节数组的形式存在, 内部结构实现上类似于
Java中的ArrayList - 采用预分配冗余空间的方式来减少内存的分配, 不过刚开始创建字符串的时候不会多分配冗余空间,因为大多时候不会使用
append操作来修改字符串, 也就不会存在字符串扩容导致的内存重新分配 - 扩容的时候,1M以下扩容是直接加倍,1M以上每次扩容只会增加1M内存,字符串最大长度为512M
- 字符串底层有两种存储方式,长度特别短的时候,使用
emb(embstr)形式存储,长度比较长的情况下采用raw形式存储
list列表
- Redis中的列表是一种链表结构,不是数组,所以插入和删除比较快,但是索引定位较慢,相对来说查找元素也就比较慢了
- 早期版本的话列表元素较少的情况下会使用一块连续的内存存储,也就是
ziplist 压缩列表的结构实现. 元素较多的情况下,使用的是普通双向链表LinkedList的结构。但因为链表附加的指针占用空间消耗问题,后面代替使用了quicklist快速链表的结构
quicklist快速链表
quicklist是ziplist和linkedlist的混合体,它linkedlist按段切分,每一段使用ziplist来紧凑存储,多个ziplist用双向指针串接起来
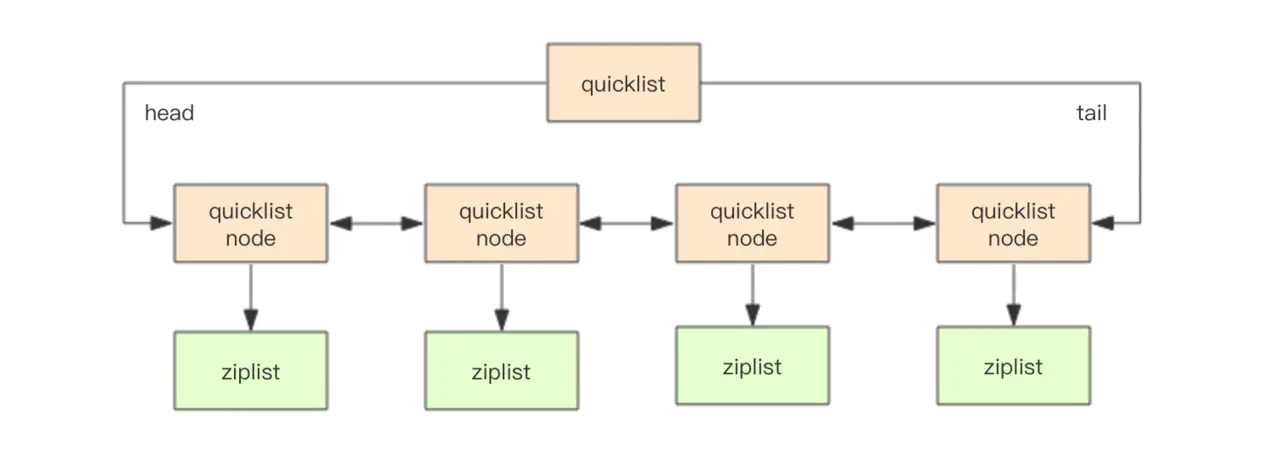
- quicklist内部默认单个 ziplist 长度为 8k字节,由配置参数
list-max-ziplist-size决定, 超出规定长度的话就会新起一个 - 为了进一步节约内存空间,Redis还会对ziplist进行压缩存储,使用
LZF算法压缩, 压缩的实际深度可以通过配置参数list-compress-depth决定
常用操作:
Redis 的列表结构常用来做异步队列使用。将需要延后处理的任务结构体序列化成字符串塞进 Redis 的列表,另一个线程从这个列表中轮询数据进行处理
> rpush
> lpop
> rpop
# 以下操作为O(n)操作,慎用
> lindex # 获取指定索引位置的值
> lrange # 遍历指定索引范围的值
> ltrim books 1 -1 # 保留books列表索引【1 到 -1】区间的值
hash哈希
Redis中的hash实现跟Java中的HashMap实现基本类似,底层也是基于数组+链表的数据结构
不同的是:
- Redis字典中的值只能是字符串
- 扩容条件不一样
- Java的HashMap的rehash操作是一次性全部rehash。Redis为了高性能,不能堵塞服务,所以采用了
渐进式rehash策略
扩容实现
扩容条件:
一般来说,当元素个数达到一维数组的长度时就会进行扩容,扩容的新数组是原来的两倍。不过如果Redis正在做bgsave(后台异步执行快照操作进行RDB持久化),为了减少内存页的过多分离(Copy On Write机制,详细参考: COW奶牛!Copy On Write机制了解一下),Redis尽量不去扩容,但是如果hash表已经非常满了,达到了数组长度的5倍还是会进行强制扩容
扩容实现:
渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个 hash 结构,然后在后续的定时任务中以及 hash 操作指令中,循序渐进地将旧 hash 的内容一点点迁移到新的 hash 结构中, 当搬迁完成了,就会使用新的hash结构取而代之
常用操作:
> hset
> hmset # 批量set
> hget
> hgetall # entries(), 同时获取所有的key、value
set集合
Redis中的set集合类似于Java中的HashSet, 内部实现相当于一个特殊的字典,元素全部当作key来存放,value值全部为空值,其内部键值对是无序且唯一的。
常用操作: sadd,spop,smembers,sunion 等
set结构可以用来存储活动中奖的用户ID,因为有去重功能
zset
类似于 Java 的 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。
实现方式:
- ziplist:满足元素数量少于128的时候每个元素的长度小于64字两个条件的时候使用此结构
- skiplist:不满足上述两个条件就会使用跳表,具体来说是组合了map和skiplistmap用来存储member到score的映射,这样就可以在O(1)时间内找到member对应的分数skiplist按从小到大的顺序存储分数skiplist每个元素的值都是[score,value]对
常用操作: zadd,zrange,zrem,zcard等
跳跃列表
链表+多层索引
思考:为什么使用跳表而不是红黑树(平衡二叉树)?
- 两者时间复杂度一样,跳表实现起来更为简单
- 并发插入或者删除元素的时候,平衡二叉树可能需要做一些rebalance的操作,这样的操作可能会涉及到整个树的其他部分,而跳表的操作影响更局部一点,这方面性能稍微好点
- 在使用
ZRANGE命令这种范围查找的情况下利用跳表里面的双向链表,可以方便地操作。另外还有缓存区域化(cache locality),所以效率不会比平衡树差
参考链接:
Redis的线程IO模型
Redis是单线程的, 虽然在新版本中引入了多线程,但多线程部分只是用来处理网络数据的读写和协议解析, 提升网络IO效率
单线程的Redis为什么那么快
- 绝大部分是内存操作,非常快
- 因为是单线程,也就避免了上下文切换和资源竞争的问题
- 采用了非阻塞IO-多路复用
参考链接
Redis持久化
Redis为持久化提供了两种方式:
- RDB快照:在指定时间间隔内对数据进行快照存储,是一次全量备份
- AOF日志文件: 内存记录数据修改的指令日志记录,是连续增量备份
Redis4.0后提供了混合持久化的功能
RDB
相关配置:
# 时间策略, 定时自动触发
save 900 1
save 300 10
save 60 10000
# 文件名称
dbfilename dump.rdb
# 文件保存路径
dir /home/work/app/redis/data/
# 如果持久化出错,主进程是否停止写入
stop-writes-on-bgsave-error yes
# 是否压缩
rdbcompression yes
# 导入时是否检查
rdbchecksum yes
RDB持久化的触发有两种: 自己手动触发与Redis定时触发
手动触发
save: 会阻塞当前Redis服务器,直到持久化完成,线上禁止使用bgsave: 会fork出一个子进程,由子进程负责持久化过程,因此阻塞只会发生在fork子进程的时候
save命令不常用,bgsave的执行流程如下:
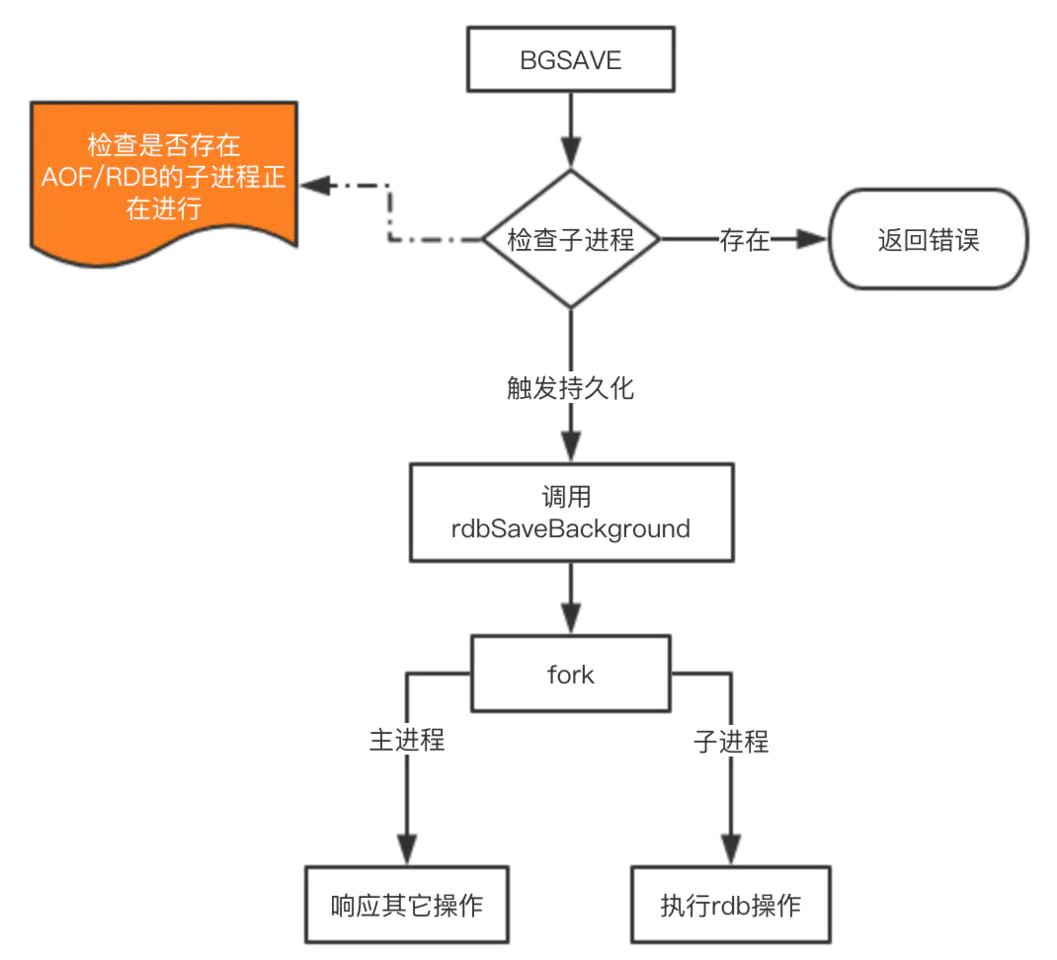
bgsave的原理
fork: redis通过fork创建子进程来进行bgsave操作cow:copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来
自动触发
自动触发的场景:
- 根据配置文件里配置的
save m n规则自动触发 - 从节点全量复制时,主节点发送rdb文件给从节点完成复制操作,主节点会触发
bgsave - 执行
debug reload时 - 执行
shutdown时,如果没有开启aof,也会触发
AOF
相关配置:
# 是否开启aof
appendonly yes
# 文件名称
appendfilename "appendonly.aof"
# 同步方式
appendfsync everysec
# aof重写期间是否同步
no-appendfsync-on-rewrite no
# 重写触发配置
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# 加载aof时如果有错如何处理
aof-load-truncated yes
# 文件重写策略
aof-rewrite-incremental-fsync yes
AOF的整个流程大体来看可以分为两步,一步是命令的实时写入(如果是 appendfsync everysec 配置,会有1s损耗),第二步是对aof文件的重写。
Redis 会在收到客户端修改指令后,进行参数校验进行逻辑处理后,如果没问题,就立即将该指令文本存储到 AOF 日志中,也就是先执行指令才将日志存盘。这点不同于leveldb、HBase等存储引擎,它们都是先存储日志再做逻辑处理。
AOF重写
Redis 在长期运行的过程中,AOF 的日志会越变越长。如果实例宕机重启,重放整个 AOF 日志会非常耗时,导致长时间 Redis 无法对外提供服务。所以需要对 AOF 日志瘦身,也就是重写。
Redis 提供了 bgrewriteaof 指令用于对 AOF 日志进行瘦身。其原理就是开辟一个子进程对内存进行遍历转换成一系列 Redis 的操作指令,序列化到一个新的 AOF 日志文件中。序列化完毕后再将操作期间发生的增量 AOF 日志追加到这个新的 AOF 日志文件中,追加完毕后就立即替代旧的 AOF 日志文件了
日志丢失
AOF 日志是以文件的形式存在的,当程序对 AOF 日志文件进行写操作时,实际上是将内容写到了内核为文件描述符分配的一个内存缓存中,然后内核异步将数据刷回到磁盘. 那么机器如果突然宕机,日志内容还没完全写入到磁盘中就会出现日志丢失的情况。
Linux 的glibc提供了fsync(int fd)函数可以将指定文件的内容强制从内核缓存刷到磁盘。在生产环境的服务器中,Redis 通常是每隔 1s 左右执行一次 fsync 操作,周期 1s 是可以配置的。这是在数据安全性和性能之间做了一个折中,在保持高性能的同时,尽可能使得数据少丢失
参考链接
Redis的同步机制
Redis可以使用主从同步,从从同步。第一次同步时,主节点做一次bgsave,并同时将后续修改操作记录到内存buffer,待完成后将rdb文件全量同步到复制节点,复制节点接受完成后将rdb镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程
Redis事务
得益于Redis的单线程模型,所以其事务模型使用起来很简单。
每个事务的操作都有 begin、commit 和 rollback,begin 指示事务的开始,commit 指示事务的提交,rollback 指示事务的回滚。
Redis 在形式上看起来也差不多,分别是 multi/exec/discard。multi 指示事务的开始,exec 指示事务的执行,discard 指示事务的丢弃
Redis的缓存失效机制
作为缓存系统都要定期清理无效数据,就需要一个主键失效和淘汰策略
过期删除策略
redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定期遍历这个字典来删除到期的 key。除了定期删除之外,它还会使用惰性策略来删除过期的 key,所谓惰性策略就是在客户端访问这个 key 的时候,redis 对 key 的过期时间进行检查,如果过期了就立即删除。定时删除是集中处理,惰性删除是零散处理
6种淘汰策略
当Redis内存超出 maxmemory 限制时,内存的数据会开始和磁盘产生频繁的交换 (swap),这会让 Redis 的性能急剧下降,因此Redis 提供了几种淘汰策略:
-
noeviction: 不会继续服务写请求 (DEL 请求可以继续服务),读请求可以继续进行。这样可以保证不会丢失数据,但是会让线上的业务不能持续进行。这是默认的淘汰策略。 -
volatile-lru: 尝试淘汰设置了过期时间的 key,最少使用的 key 优先被淘汰。没有设置过期时间的 key 不会被淘汰,这样可以保证需要持久化的数据不会突然丢失。 -
volatile-ttl: 淘汰设置了过期时间的 key, key 的剩余寿命ttl的值越小越优先被淘汰。 -
volatile-random: 淘汰设置了过期时间的 key, 不过淘汰的 key 是过期 key 集合中随机的 key。 -
allkeys-lru: 区别于 volatile-lru,这个策略要淘汰的 key 对象是全体的 key 集合,而不只是过期的 key 集合。这意味着没有设置过期时间的 key 也会被淘汰。 -
allkeys-random: 从全体的 key 集合中随机挑选淘汰
Redis的哈希槽
Redis集群没有使用一致性hash,而是引入了哈希槽的概念,Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽
Redis中的管道
将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读取该答复,提升IO效率。
Redis的集群
-
Redis Sentinal着眼于高可用,在master宕机时会自动将slave提升为master,继续提供服务。
-
Redis Cluster着眼于扩展性,在单个redis内存不足时,使用Cluster进行分片存储
缓存场景问题
缓存穿透
要查询的数据在缓存和数据库中都不存在,可能因此恶意高并发请求攻击导致后台DB崩溃
解决思路:
- 缓存空值: 第一次查询后,针对不存在的key设置其值为空值,后续对这个key的请求直接就返回空, 但要注意设置好过期时间
- BloomFilter: 利用布隆过滤器判断元素(某个key)是否存在
缓存雪崩
设置缓存时采用了相同的过期时间,然后某一时刻出现大规模的缓存失效,从而导致去查询数据库,进一步可能导致数据库压力过大的情况
解决思路:
- 打散过期时间设置: 比如在原有过期时间设置的基础上加上一个随机值,降低缓存过期时间的重复率
- 限流 && 降级, 避免后台DB因请求压力过大而崩溃
- 使用锁或队列,避免过多请求同一时刻落到后台DB上
- 给每一个缓存数据value值添加一个缓存标记时间,这个时间比实际设置的缓存时间要早,当读取到缓存标记失效时,会通知其他线程去更新缓存,实际还能返回旧缓存的数据直到更新缓存完成
缓存击穿
某个时间点这个缓存过期了,恰好此时有很多针对这个缓存的查询请求,发现缓存失效后会从后端DB加载数据并更新到缓存,请求量过大的情况下可能会导致DB压力过大而崩溃
注意:
缓存击穿和缓存雪崩是不同的,前者针对的是单个key,而雪崩是很多key
解决思路:
参考缓存雪崩,类似
缓存预热
系统上线后,先将相关的缓存数据加载到缓存中,避免了第一次请求查询从DB中加载更新缓存
缓存更新
先更新数据库再更新缓存
不适用,有以下问题:
- 线程不安全,可能造成脏数据。比如多个写请求到达,本来应该是将最后的写请求数据更新到缓存,但可能因为网络波动原因,实际更新到缓存中的数据是前面其中某一次写的数据
- 不适合写多读少的场景,缓存被频繁更新,浪费性能
先删缓存,再更新数据库
问题分析:
同时有一个请求A进行更新操作,另一个请求B进行查询操作,那么会出现如下情形:
- 请求A进行写操作,删除缓存
- 请求B查询发现缓存不存在
- 请求B去数据库查询得到旧值
- 请求B将旧值写入缓存
- 请求A将新值写入数据库
上述情况就会导致不一致的情形出现。而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据
解决方案: 延时双删策略
- 先淘汰缓存
- 再写数据库(这两步和原来一样)
- 休眠一个短时间比如1s,再次淘汰缓存
这样就可以将1s内产生的脏数据清除了,另外这个休眠时间需要根据业务实际场景评估
先更新数据库,再删除缓存(常用策略)
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。命中:应用程序从cache中取数据,取到后返回。更新:先把数据存到数据库中,成功后,再让缓存失效,删除缓存
问题分析:
同样假设有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生
- 缓存刚好失效
- 请求A查询数据库,得一个旧值
- 请求B将新值写入数据库
- 请求B删除缓存
- 请求A将查到的旧值写入缓存
发生数据不一致的前提条件是需要步骤3的写数据库操作比2的读数据库操作耗时更短,但数据库的读操作的速度远快于写操作的,这种概率还是很低的。