
发展历程
新事物的产生根植于旧矛盾的解决与新矛盾的诞生,其本质是矛盾运动的阶段性结果;
矛盾是事物内在的普遍属性,而发展是通过矛盾的不断“产生-解决-再生产”实现的动态过程。
大数据技术的产生本质上是存储与计算的矛盾,而发展则是“数据规模的爆炸式增长与计算效率、实时性需求之间的持续博弈”,这一矛盾推动技术不断革新。
数据规模膨胀 vs 存储与计算能力不足
- 矛盾本质:传统单机系统无法承载指数级增长的数据量(从TB到PB甚至EB级)。
- 技术突破:
- 分布式存储(如HDFS、云存储)将数据分散到多节点,解决存储瓶颈。
- 分布式计算框架(如MapReduce、Spark)通过并行处理提升计算吞吐量。
批处理延迟 vs 实时性需求
- 矛盾本质:早期Hadoop仅支持离线批处理(小时/天级延迟),但业务需要秒级甚至毫秒级响应。
- 技术突破:
- 内存计算(Spark)减少磁盘I/O,提升批处理速度。
- 流处理引擎(Flink、Kafka Streams)实现“数据在流动中计算”,满足实时分析需求。
数据多样性 vs 处理范式单一性
- 矛盾本质:结构化、半结构化、非结构化数据(文本、图像等)的复杂性,与传统数据库的单一处理模式不兼容。
- 技术突破:
- 多模态存储:NoSQL(如MongoDB)、数据湖(如Delta Lake)支持灵活的数据模型。
- 混合计算引擎:Spark支持批处理、流处理、图计算和机器学习,实现“一栈式”处理。
资源静态分配 vs 动态弹性需求
- 矛盾本质:固定集群资源导致利用率低,无法应对业务波动。
- 技术突破:
- 云原生架构:Kubernetes实现容器化弹性扩缩容,Serverless(如AWS Lambda)按需分配资源,降低成本。
集中式治理 vs 分布式复杂性
- 矛盾本质:数据分散在多个系统(数据库、数据湖、流平台)中,难以统一管理和保障质量。
- 技术突破:
- 数据编织(Data Fabric):通过元数据管理(如Apache Atlas)、自动化管道(如Airflow)实现跨平台数据协同。
- 湖仓一体(Lakehouse):Delta Lake等工具融合数据湖的灵活性与数仓的治理能力。
总结 - 矛盾驱动创新
大数据技术的演进本质是**“不断打破旧平衡,建立新平衡”**的过程:
- 从 Hadoop的“以存储换计算”,到 Spark的“以内存换速度”;
- 从 批处理的确定性,到 流处理的不确定性应对;
- 从 固定资源分配,到 云原生的弹性伸缩。
每一次矛盾的激化都催生了新技术的诞生,而未来趋势(如边缘计算、AI原生数据平台)仍将围绕这一核心矛盾展开。
技术体系
生态架构
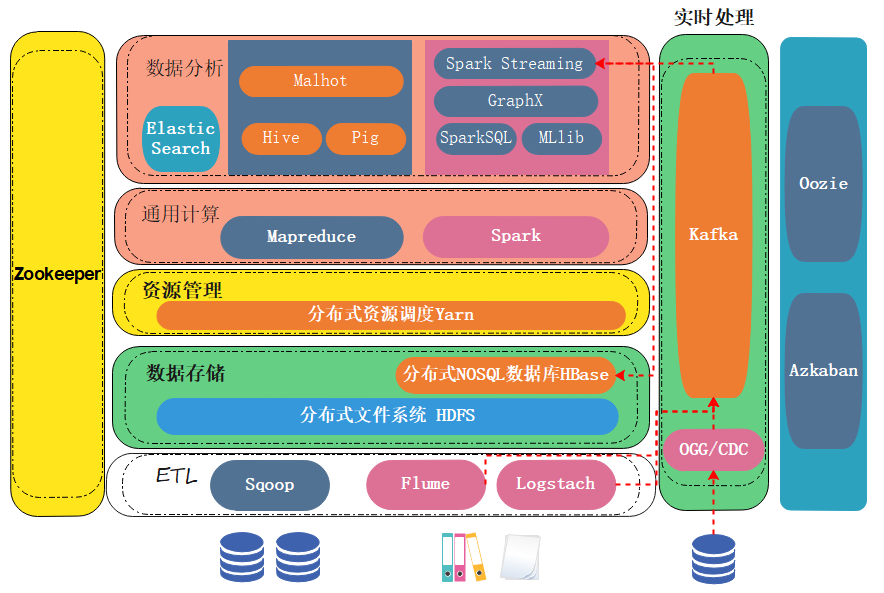
数据采集层
- 目标:从多源(数据库、日志、传感器等)高效采集数据。
- 工具:
- 批量采集:Sqoop(关系数据库 ↔ Hadoop)、Flume(日志收集)。
- 实时采集:Kafka(分布式消息队列)、Debezium(CDC变更捕获)。
- 爬虫:Scrapy、Apache Nutch(网页数据抓取)。
数据存储层
- 分布式文件系统:
- HDFS:Hadoop生态核心存储,适合冷数据。
- 对象存储:AWS S3、阿里云OSS(云原生场景)。
- NoSQL数据库:
- 键值型:Redis(内存缓存)、DynamoDB(高并发)。
- 列存储:HBase(海量随机读写)、Cassandra(高可用)。
- 文档型:MongoDB(灵活JSON结构)。
- 数据湖:Delta Lake、Iceberg(支持ACID事务的湖仓一体架构)。
资源管理与调度层
- 集群管理:
- YARN:Hadoop资源调度器。
- Kubernetes:容器化编排,支持混合云部署。
- 工作流引擎:
- Airflow:任务依赖管理与定时调度。
- DolphinScheduler:国产可视化调度工具。
数据计算层
- 批处理:
- MapReduce:Hadoop原生计算模型,适合离线任务。
- Spark SQL:兼容SQL语法,优化复杂ETL流程。
- 流处理:
- Flink:低延迟流处理,支持状态管理和窗口计算。
- Spark Streaming:微批处理,与Spark生态无缝集成。
- 交互式查询:
- Presto:多数据源联邦查询,适合即席分析。
- ClickHouse:列式存储,OLAP场景极速响应。
数据分析与挖掘层
- 机器学习:
- Spark MLlib:分布式机器学习库。
- TensorFlow/PyTorch:深度学习框架,与大数据平台集成(如Horovod)。
- 数据可视化:
- Tableau/Power BI:商业智能工具。
- Superset/Grafana:开源可视化仪表盘。
- 图计算:Neo4j(图数据库)、GraphX(Spark图处理库)。
数据治理与安全
- 元数据管理:Apache Atlas(数据血缘追踪)。
- 数据质量:Great Expectations(数据校验框架)。
- 安全合规:Kerberos(认证)、Ranger(权限控制)、GDPR合规工具。
数据分层
在大数据架构中,数据分层(Data Layering)是一种将数据按处理阶段、用途和访问需求划分为不同层次的设计方法,旨在提高数据管理效率、降低冗余、优化性能,并支持多样化的分析场景。
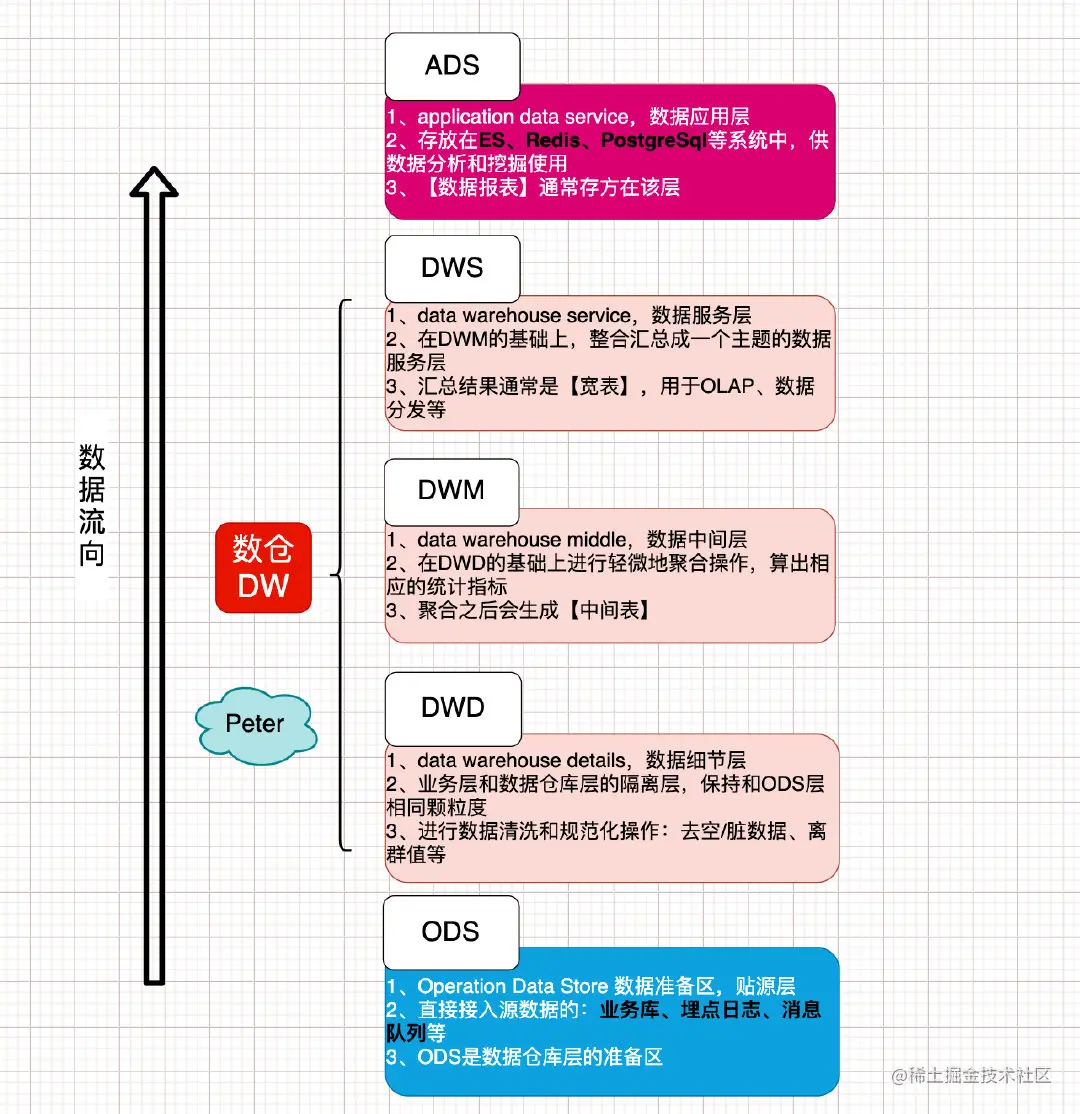
原始数据层
数据运营层:Operation Data Store 数据准备区,也称为贴源层。
输入表:无(直接对接数据源)
输出表:原始数据表(Raw Data Tables)
示例:
- 用户点击日志表(ods_user_click_log)
{
"timestamp": "2023-10-01T14:22:35+08:00",
"user_id": "u_12345",
"event": "click_product_detail",
"device": "Android 12|Xiaomi 13 Pro",
"ip": "192.168.1.100",
"extra": "{'product_id':'p_678', 'page_num':3}"
}
- MySQL订单表快照(ods_order_mysql)
| order_id | user_id | amount | currency | create_time | status |
|---|---|---|---|---|---|
| 1001 | u_123 | 299.00 | CNY | 2023-10-01 14:25:00 | pending |
| 1002 | u_456 | 150.50 | USD | 2023-10-01 14:30:00 | completed |
特点:保留原始数据的所有字段,包含冗余、未清洗的信息。
清洗与标准化层
输入表:ods_user_click_log, ods_order_mysql
输出表:清洗后的结构化表
示例:
- 标准化点击日志表(cleaned_user_click)
| log_id | event_time | user_id | event_type | device_os | device_model | ip_hash | product_id | page_num |
|---|---|---|---|---|---|---|---|---|
| 1 | 2023-10-01 14:22:35 | 12345 | product_detail | Android | Xiaomi 13 Pro | a1b2c3d4 | p_678 | 3 |
处理逻辑:
- 解析
extra字段中的JSON,提取product_id和page_num。 - 将
user_id统一为纯数字(去除前缀u_)。 - 对
ip字段进行哈希脱敏。 - 拆分
device字段为操作系统和设备型号。
- 统一订单表(cleaned_order)
| order_id | user_id | amount_cny | create_time | status_code |
|---|---|---|---|---|
| 1001 | 123 | 299.00 | 2023-10-01 14:25:00 | 1 |
| 1002 | 456 | 1053.50 | 2023-10-01 14:30:00 | 2 |
处理逻辑:
- 转换货币为CNY(假设1 USD=7.0 CNY)。
- 映射状态码(pending→1, completed→2)。
整合与建模层
数据细节层:data warehouse details,DWD/Dimensional Model
该层是业务层和数据仓库的隔离层,保持和ODS层一样的数据颗粒度;主要是对ODS数据层做一些数据的清洗和规范化的操作,比如去除空数据、脏数据、离群值等。
数据中间层:Data Warehouse Middle,DWM;
该层是在DWD层的数据基础上,对数据做一些轻微的聚合操作,生成一些列的中间结果表,提升公共指标的复用性,减少重复加工的工作。
输入表:cleaned_user_click, cleaned_order
输出表:维度表 + 事实表
示例:
- 维度表:用户维度(dim_user)
| user_id | name | gender | age | reg_date | vip_level |
|---|---|---|---|---|---|
| 123 | 张三 | M | 28 | 2022-01-01 | 2 |
| 456 | 李四 | F | 35 | 2021-05-15 | 3 |
- 事实表:订单交易事实表(fact_order)
| order_id | user_id | product_id | amount | order_time | payment_time |
|---|---|---|---|---|---|
| 1001 | 123 | p_678 | 299.00 | 2023-10-01 14:25:00 | 2023-10-01 14:26:05 |
| 1002 | 456 | p_901 | 1053.50 | 2023-10-01 14:30:00 | 2023-10-01 14:31:20 |
建模逻辑:
- 通过
user_id关联事实表与维度表,支持“订单金额按性别分析”等场景。
汇总与聚合层
数据服务层:Data Warehouse Service,DWS/Data Mart;
该层是基于DWM上的基础数据,整合汇总成分析某一个主题域的数据服务层,一般是宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
一般来说,该层的数据表会相对较少;一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。
输入表:fact_order, dim_user
输出表:预聚合宽表
示例:
- 每日用户消费汇总表(dws_user_daily_spend)
| date | user_id | gender | total_amount | order_count | avg_amount |
|---|---|---|---|---|---|
| 2023-10-01 | 123 | M | 299.00 | 1 | 299.00 |
| 2023-10-01 | 456 | F | 1053.50 | 1 | 1053.50 |
计算逻辑:
- 按天聚合每个用户的订单总金额、订单数、平均金额。
- 关联维度表获取性别字段,支持快速生成“不同性别用户消费对比”报表。
应用与服务层
数据应用层:Application Data Service,ADS;
该层主要是提供给数据产品和数据分析使用的数据,一般会存放在ES、Redis、PostgreSql等系统中供线上系统使用;也可能存放在hive或者Druid中,供数据分析和数据挖掘使用,比如常用的数据报表就是存在这里的。
输入表:dws_user_daily_spend
输出表:业务接口或报表
示例:
- BI报表数据(ads_bi_gender_spend)
| 日期 | 性别 | 总消费金额 | 订单数 |
|---|---|---|---|
| 2023-10-01 | 男 | 299.00 | 1 |
| 2023-10-01 | 女 | 1053.50 | 1 |
- API响应(用户画像接口)
{
"user_id": 123,
"last_purchase_date": "2023-10-01",
"total_spend_7d": 299.00,
"favorite_category": "电子产品"
}
特点:数据高度聚合,字段命名符合业务术语,可直接用于展示或决策。
ETL
核心定义
ETL 是数据从源系统到目标存储的标准化流程,包含三个阶段:
- Extract(抽取):从异构数据源提取原始数据。
- Transform(转换):清洗、标准化、加工数据。
- Load(加载):将处理后的数据写入目标存储。
技术栈与工具
| 阶段 | 典型工具 |
|---|---|
| Extract | Sqoop、Flume、Kafka、Debezium(CDC)、AWS Glue |
| Transform | Spark、Flink、dbt、Python Pandas、SQL |
| Load | Hive、HBase、ClickHouse、Snowflake、Redis、Elasticsearch |